Mobile app build & deployment automation at Bornfight
AuthorTomislav Smrečki
DateJun 25, 2020
Collaboration on software development projects can be difficult, and mobile apps are no exception. From simply taking care of the codebase to deployment phase, bumping app versions, updating the changelog, keeping track of test and production releases… there are a lot of factors to look after.
How productive can your team be if you have to waste some of your energy to sync on these things with your teammates? Not to mention these tasks are often repetitive and boring.

Check out why we think it’s important to streamline this, what tools do we use to do it and how they are all connected into the magical process of automated development & deployment.
Our code management system structure
The source code management system is the basis for all other tools that will follow in this blogpost. Even if you’re a single developer and, for some reason, you’re still not using some VCS, I encourage you to do that. Your code will be safely stored if something happens to your local version and you can keep track of any changes in case you need to revert some of the work.
But the more important reason is that your VCS repository will be the starting point for the rest of the automation pipeline.
We use GitLab as it offers a very nice interface and integration with their own proprietary CI/CD system. But that’s just a matter of preference – GitHub or Bitbucket, for example, are equally good.

Branching system
We use something similar to Git flow as a branching system, but we actually adjusted it to our needs. As a base, we have master and staging branches. Master branch contains tested, QA-approved code and it’s always ready for public release at a client request.
Code on staging contains all unreleased features that are yet to be tested internally and by our client. When we confirm that the staging version is OK, we merge it to the master version where it waits for the public release.
When working on something new, we create a feat branch which is the base branch for every new feature. If the feature is big and contains several sub-functionalities, we may create feat branches for each of those. For fixes, we use fix branches.
And that’s it. We found these four types of branches suited us the most, between a complex branching system and a merge conflict prone “let’s just work on one branch” system.
Commit messages
The other important thing here is to have structured commit messages.
We all get a moment of weakness or dare I say laziness, and sometimes we opt for meaningless “Update”, “Update 2”, “Fix” or “Abasdada” commit messages.
Git hooks to the rescue! Why?
Well, as you’ll find out later in text, we use semantic-release automation tool which can analyze our commit messages and generate the changelog automatically. But to do that, the commit messages need to be structured.
We use Husky Git hook to check our commit messages before they are actually committed and pushed. Each commit message will be in the following format, where scope is optional:
<type>(<scope>): <subject>For example, if I’m currently implementing a notifications feature, the commit message header would be formatted something like this:
feat(notifications): implemented FCM service
Implemented FirebaseMessagingService and set-up FCM token upload to API.As in any commit message, you can see that we can also add a body to it to explain our work into more details. Later on, when the changelog is created, all features, fixes or breaking changes will be grouped, and will also have an impact on the next build version.
Feel free to check out our MVVM template project for Android and find the commit lint rules we use for our commit messages.
Work like a machine…
Or have a machine work for you. For automation, it is necessary to have a machine that will run all of the repetitive and boring tasks for you. And might I say, it will be more efficient in those tasks than a human.
We use the raw power or EC2 service from Amazon Web Services (AWS) to run all of our automation tasks. To jumpstart the automation environment that will be able to run our tasks, we use Docker image which is pulled from the GitLab repository and which contains all of the required tools for automation. This helps us prepare Gradle, xcode, Fastlane, yarn, Firebase CLI and other tools before the automation pipeline starts.
There are many open-source Dockerfiles for Android, but you can also use our own if the configuration suits you. You’ll get a Docker image with an Android SDK, Java, yarn, bundler and even an emulator image with API25 for testing purposes.
Add some brains to the machine…
Well, now we have this entity with all of its tools, but who or what will decide how those tools are used?
Here comes the CI/CD environment. As mentioned before, GitLab has its own integrated continuous integration system which works amazingly well with the source code management system. Even the merge requests can be automatically merged when the pipeline successfully completes. But now I’m getting ahead of myself, let’s first talk about the CI/CD.
So, it’s basically a set of tasks organized into a pipeline which is triggered when you push some changes to your source code. For GitLab CI/CD run, all you have to do is install a GitLab Runner on your machine (or use one of the Shared GitLab Runners) and place a .gitlab-ci.yml configuration file into your project.
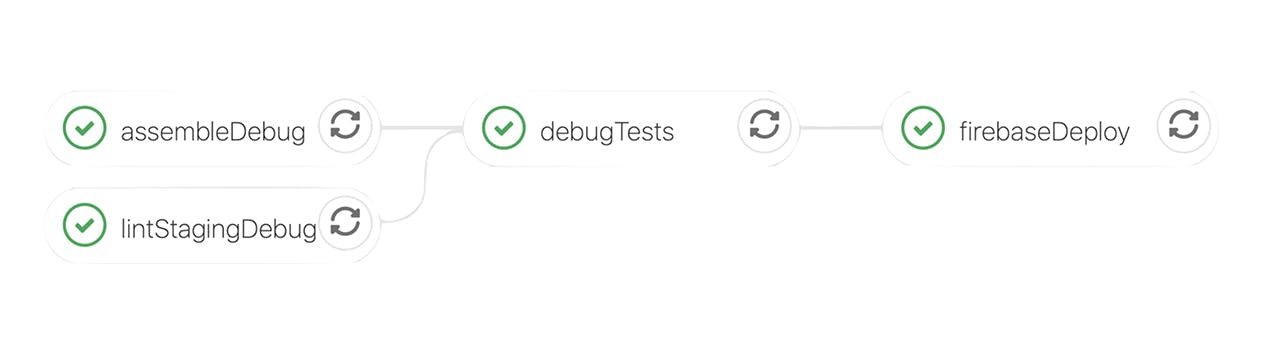
At Bornfight, we define three stages of the pipeline – build, test & deploy.
Build stage
In this stage, we check the “buildability” of the project and also we prepare the artefacts needed for further automation process.
It is here where we would run lint check on the code and try to build the app artefact (APK for example). Also, in the Android team we have something we call a Technical Information Card – it’s a document that is automatically built from the build.gradle parameters, and which provides information about supported OS version, permissions and any restrictions of the app in a non-developer readable form. It’s mostly used by QA, so they can focus their testing on edge cases that a certain OS version or a device might have.
Test stage
This one’s rather straightforward – we only have test tasks in this stage.
This stage will run unit tests and instrumentation tests. For on-device testing, we have an emulator set-up inside a Docker image. This phase will use a built debug version from the previous stage to run the emulator testing.
Deploy stage
This final stage is the most interesting, but also rather complex.
Of course, as the name says, it deals with deploying the app to our testers and users, but it will also take care of generating a changelog and bumping app version. We run the deploy stage only on our staging and master branches.
Merging a feat or fix branch to the staging branch will automatically build the test version and deploy it to our QA team for internal testing.
Merging to master branch will build the release version and automatically deploy to our QA team, but also to our client. Note that merging to master will not publish the app publicly (on Play Store or App Store). Basically, we let deployment of test and release versions happen automatically as it only goes to our testers, QA team and our client – so even if we overlook some sneaky bug, it will not end up automatically in a public store.
Deployment to the public store will actually be triggered manually via tags, so that way we keep some control over the final deployment. Pushing a tag to the master branch will finally create a release version which is deployed to the public.
So as you can see, it’s pretty simple to deploy test or release versions, but let’s explain the deployment process under the hood.
If you’re using GitLab CI, check out our gitlab-ci.yml file with CI configuration.
Deployment tools
In order to achieve this simplified deployment, we combined several tools that handle some tasks for us.
Semantic-release
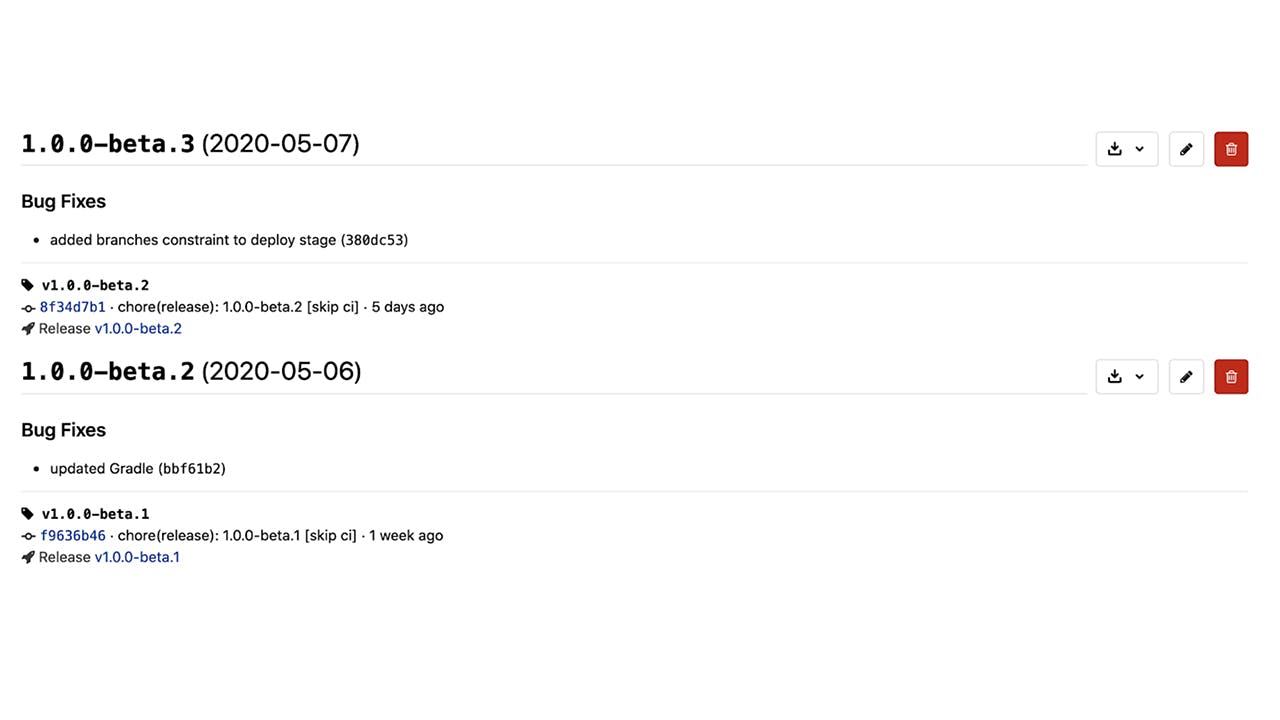
This is an automation tool which we mainly use to auto-generate the changelog and determine the next app version.
Based on the commit messages we described previously, semantic-release tool can bump the major, minor or patch version of the app. After it generates the changelog and updates the app version, the updated files are pushed back to the GitLab repository, so we always have the latest state when continuing work with new features or fixes.
Also, I’ll just mention here that when you’re developing an SDK that will be published on Maven, proper versioning is a requirement otherwise the Maven repositories will forbid you to update an artefact (for example, if you’re trying to push the SDK with the existing or lower version name than a previous one).
This really helps us a lot, so we never have to worry about versioning.
You can have a look at our semantic-release configuration file. It maps the types of commit messages to a change in patch, minor or major version. It also runs commit-analyzer, release-notes-generator and any other custom command you add.
You can also define some of the branches as prerelease branches.
Fastlane
It’s a platform that is specifically designed to help simplify Android and iOS deployment. And it has a lot of plugins which help you manipulate build & deployment of Android and iOS.
In Android, we use it to increment app version code, build the APK or App Bundle with the version name from semantic-release, and to distribute the app via Firebase or Play Store.
Finally, we use the Fastlane plugin for Slack to send Slack notifications when deployment is done, so we and our testers know when new versions are up and available.
Of course, we also have our Android configuration file publicly available, so you can consult it if you too are planning to implement a similar flow.
Nexus publish
When we develop Android SDK or we have a large app where we want to extract some of the codebase into a separate library, we use the Nexus publish plugin combined with the Maven publish plugin to deploy these libraries to a public (mostly OSS Sonatype) or a private Nexus repository.

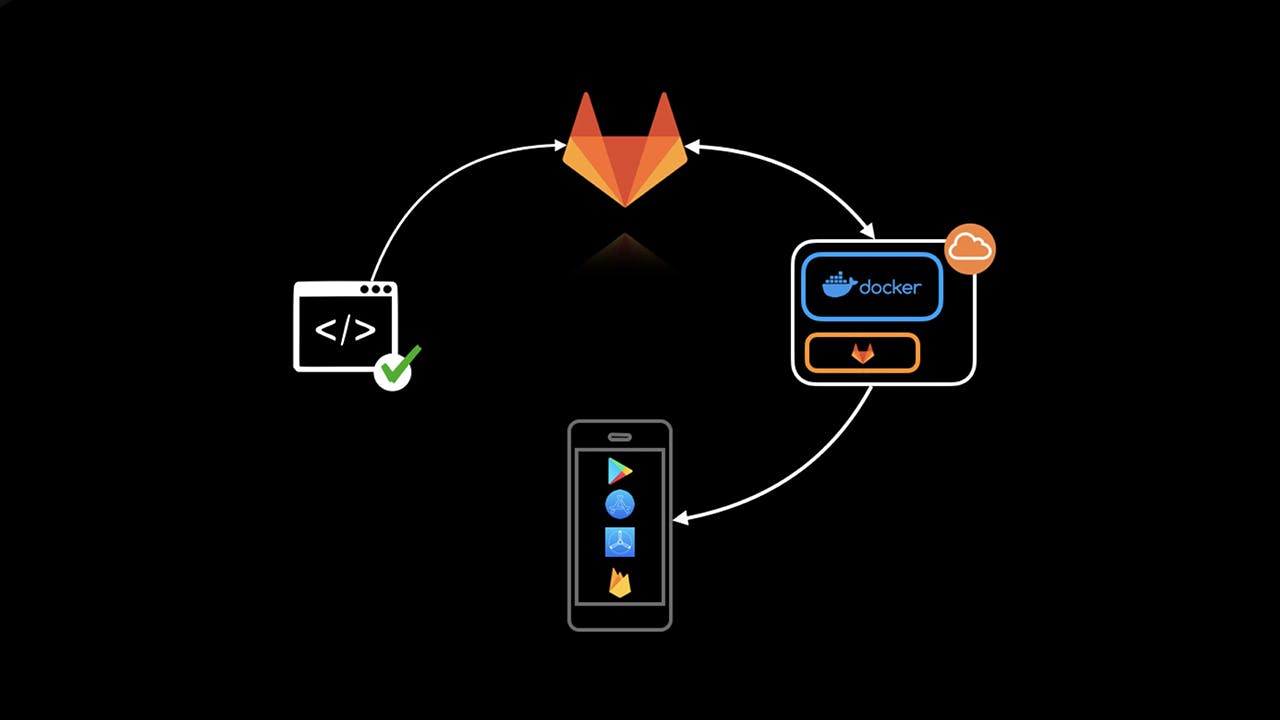
Deployment flow
Now that you’re familiar with the deployment components and process, let’s see what the final flow looks like.
- Any pushed commit will have a linted commit message which will be used for the changelog
- Merge requests to staging branch will trigger automatic deployment of the beta version (version code will have a -beta.X suffix)
- All of the commit messages are analyzed and the changelog with next version is generated
- Fastlane will take the version code and build the next APK (or App Bundle) with that version, deploy it via Firebase App Distribution or Testflight, and send notification via Slack
- If this is a library, then the SDK will be built with that version and published to Maven
- Push all of the changes and the new pre-release tag back to the GitLab (updated app/sdk version, changelog etc.)
The same process repeats if we merge the staging branch to the master, except this time the version code will not have the -beta suffix and the created tag on the GitLab will be an actual release tag (as opposed to the pre-release tag from the staging branch).
Deployment automation benefits
At Bornfight, we quickly saw the improvements in productivity and general motivation after we implemented this flow.
Developers have less to worry about when deploying the apps and we can concentrate on the code quality more. Even the testing and QA reports are more streamlined as now every fix has its own version and changelog, so we can easily link this to Jira and annotate each task with the fix version.
We set up a template project which already has all of the required configuration files and we just update the specific keys or values when starting a new project. Commit lint also didn’t get in the way because we quickly got accustomed to the proper format, so now we are very efficient at writing useful commit messages.
Of course, as this process includes a number of components, phases and tools, it’s constantly evolving and we tend to improve it even more.
We would like to hear your feedback and experience with this. What does your deployment setup look like? Did you find some other helpful tools to streamline this process even more? Let us know your thoughts or contact us if you need help setting up your own deployment automation, we’ll be glad to discuss it with you.


